1.3. Linear Models and their Algebra
Thus far we covered the probabilistic and stochastic nature of software 2.0,
which requires computations on distributed truth values such as torch.Tensor
and it's various torch.distributions. In this chapter we cover the linear
workhorses of statistical inference, which include linear models and their
linear algebra solvers, following torch.linalg accelerated by cuBLAS.
Contents
1.3.1 Prediction
TIKZ: FUNCTION/WEIGHT SPACE AND DATA SPACE
The primary goal of supervised machine learning is to recover an underlying probability distribution by inverting a function. In other words, the process of learning maps a data space of observable inputs and outputs to a function space. Elements in the data space are referred to as data, evidence, and observables, while elements in the function space are referred to as hypotheses, and models. Once a function has been learned, evaluation of said function is used to predict future quantities of interest.
More precisely, given a dataset with the data space being comprised of high dimensional input and output vector spaces and , the underlying probability distribution needs to be recovered, and evaluated for future predictions.
The primary distinction in predictive models is that of parametricity — whether the models have a fixed or variable number of parameters with respect to the size of the dataset . This chapter will use language modeling as a running example to introduce the workhorses of both parametric and non-parametric models1.
1.3.2 Parametric Models
Linearly Parametric
The hello world of learning machines is that of curve fitting Consider the data above. The linear modeling assumption is to assume that the underlying function to generate the observables is linear in the latent weights .
Model
% This quicksort algorithm is extracted from Chapter 7, Introduction to Algorithms (3rd edition)
\begin{algorithm}
\caption{Quicksort}
\begin{algorithmic}
\PROCEDURE{Quicksort}{}
\IF{}
\STATE \CALL{Partition}{}
\STATE \CALL{Quicksort}{}
\STATE \CALL{Quicksort}{}
\ENDIF
\ENDPROCEDURE
\PROCEDURE{Partition}{}
\STATE
\STATE
\FOR{ \TO }
\IF{}
\STATE
\STATE exchange
with
\ENDIF
\STATE exchange with
\ENDFOR
\ENDPROCEDURE
\end{algorithmic}
\end{algorithm}
import torch
# ---- toy data ----
torch.manual_seed(0)
N, D = 1000, 3
X = torch.randn(N, D)
w_true = torch.tensor([2.0, -3.0, 0.5])
b_true = 0.7
y = X @ w_true + b_true + 0.1*torch.randn(N)
# ---- closed-form least squares: beta = argmin ||A beta - y||_2 ----
A = torch.hstack([X, torch.ones(N, 1)]) # add intercept column
beta = torch.linalg.lstsq(A, y.unsqueeze(-1)).solution # shape [D+1, 1]
w_hat, b_hat = beta[:-1, 0], beta[-1, 0]
print("ŵ:", w_hat)
print("b̂:", b_hat.item())
# quick check
y_hat = X @ w_hat + b_hat
mse = torch.mean((y_hat - y)**2)
print("MSE:", mse.item())
- model
- inference
- eval
Host
% This quicksort algorithm is extracted from Chapter 7, Introduction to Algorithms (3rd edition)
\begin{algorithm}
\caption{Quicksort}
\begin{algorithmic}
\PROCEDURE{Quicksort}{}
\IF{}
\STATE \CALL{Partition}{}
\STATE \CALL{Quicksort}{}
\STATE \CALL{Quicksort}{}
\ENDIF
\ENDPROCEDURE
\PROCEDURE{Partition}{}
\STATE
\STATE
\FOR{ \TO }
\IF{}
\STATE
\STATE exchange
with
\ENDIF
\STATE exchange with
\ENDFOR
\ENDPROCEDURE
\end{algorithmic}
\end{algorithm}
#![allow(unused)] fn main() { // Click the eye icon in the upper right to reveal the Rust implementation. fn quicksort() { // This line will be hidden initially let x = 10; // ... } }
Device
% This quicksort algorithm is extracted from Chapter 7, Introduction to Algorithms (3rd edition)
\begin{algorithm}
\caption{Quicksort}
\begin{algorithmic}
\PROCEDURE{Quicksort}{}
\IF{}
\STATE \CALL{Partition}{}
\STATE \CALL{Quicksort}{}
\STATE \CALL{Quicksort}{}
\ENDIF
\ENDPROCEDURE
\PROCEDURE{Partition}{}
\STATE
\STATE
\FOR{ \TO }
\IF{}
\STATE
\STATE exchange
with
\ENDIF
\STATE exchange with
\ENDFOR
\ENDPROCEDURE
\end{algorithmic}
\end{algorithm}
#![allow(unused)] fn main() { // Click the eye icon in the upper right to reveal the Rust implementation. fn quicksort() { // This line will be hidden initially let x = 10; // ... } }
Non-linearly Parametric
model solve: sgd/adam eval
1.3.3 Non-parametric Models
Gaussian Processes
- visualization
- circuit
- math
- code
Although parametically non-linear deep neural networks have had major success in generative language modeling (covered in the next section), there are properties that non-parametric models exhibit in which industrial large language models lack. Thus, they are covered in this book, to serve as foundation for the discipline of machine learning systems.
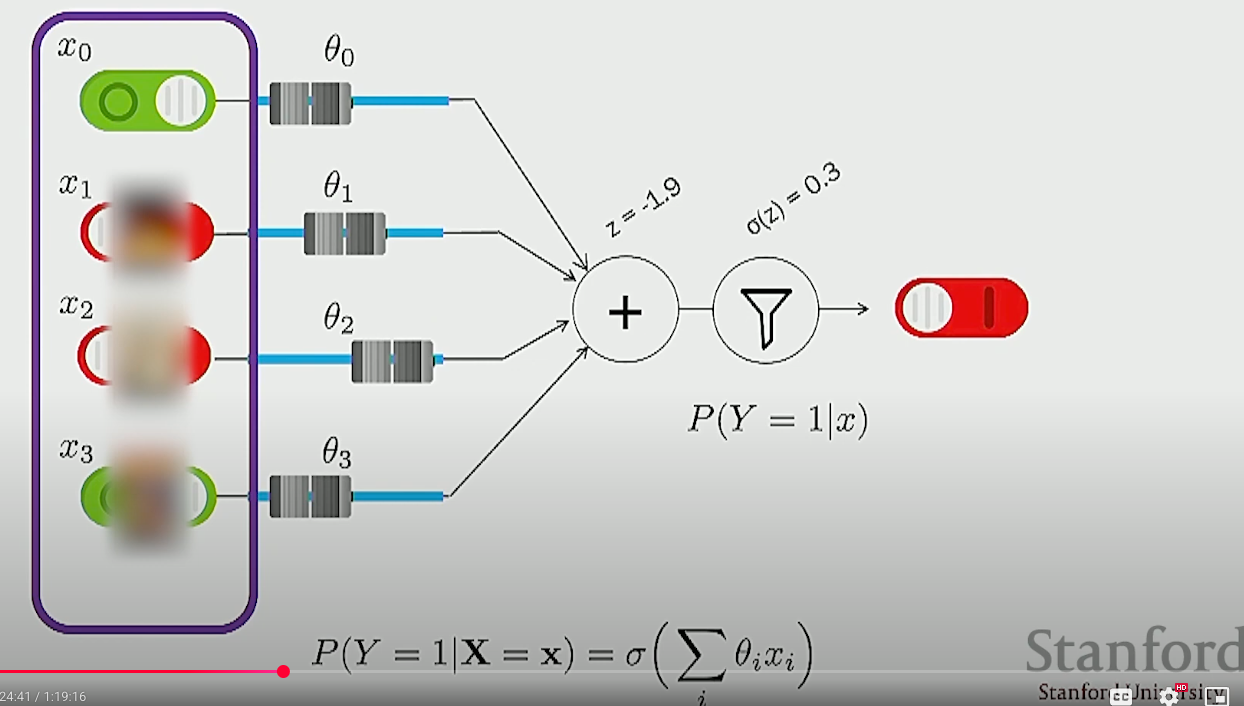
The logistic regression model is a discriminative with a decision boundary (in the case of , is usually set to so as to divide the mass by 2) that assumes that the parameter is affine with respect to . That is,
where is a non-linear function , and where is referred to as the logit since the inverse is defined as the log odds ratio.
With the model now defined, the parameter needs to be estimated from the data . This is done by using the negatve log likelihood as the loss function to minimize so that is fixed with respect to the data
where todo kl->ce.
where is implemented by first evaluating the gradient and then iteratively applying gradient descent for each time step , .
First, to evaluate the gradient, , the negative log likelihood as loss function is simplified by defining so that . Note that is not the target label but the probability of the target label. Then, since the derivative is linear with the derivative of the sum is the sum of the derivatives where , taking the derivative for a single example for a single parameter where looks like
and so the evaluating the derivative of all examples where looks like
And so the swapping indices for the entire gradient gives . Recall now that the second step in implementing after taking is to then iteratively apply gradient descent for each time step , .